Risicocijfers – het aantal ongevallen gedeeld door de afgelegde afstand – worden gebruikt om het veiligheidsniveau van verschillende groepen met elkaar te vergelijken, zoals verschillende vervoerswijzen of verschillende wegtypen. Risicocijfers zijn belangrijk bij het berekenen van verkeersveiligheidseffecten tijdens de planfase van infrastructurele projecten, bij het monitoren van ontwikkelingen in de verkeersveiligheid en bij de prioritering van bepaalde wegen/wegtypen voor maatregelen.
In de periode 1985-2007 heeft SWOV risicocijfers bepaald voor de verschillende typen wegen in Nederland. Vanwege een gebrek aan voldoende betrouwbare verkeersintensiteitsgegevens op vooral gebiedsontsluitingswegen en erftoegangswegen, zijn deze risicocijfers sinds 2007 niet meer geactualiseerd. Voor wegbeheerders is het daardoor soms lastig om de verkeersveiligheidseffecten van grote infrastructurele ingrepen op het onderliggend wegennetwerk inzichtelijk te maken, met name op het niveau van wegtype/snelheidslimiet.
Inmiddels zijn er meer data beschikbaar om risicocijfers en ook ongevallendichtheden (het aantal ongevallen per kilometer weglengte) te kunnen schatten. Daarom heeft SWOV een poging gedaan om op basis van beschikbare databronnen de risicocijfers en ongevallendichtheden – samen ‘kencijfers’ genoemd – voor verschillende wegtypen op het onderliggend weggennet te actualiseren.[1]
Het onderzoek
In de eerste plaats is nagegaan welke databronnen hiervoor op dit moment beschikbaar en bruikbaar zijn. In de tweede plaats is een methode ontwikkeld om ongevallendichtheden en risicocijfers te schatten op basis van de beschikbare gegevens. Deze methode is vervolgens toegepast om tot geactualiseerde ongevallendichtheden en risicocijfers per wegtype te komen. Toepassing van de methode geeft ook inzicht in de betrouwbaarheid van de risicocijfers en in de haalbaarheid van een meer structurele actualisatie van risicocijfers.
Beschikbare databronnen
Om risicocijfers te schatten is informatie nodig over het wegenareaal, verkeersintensiteiten en het aantal ongevallen op deze wegen. Binnen dit onderzoek zijn de mogelijke bronnen hiervoor geïnventariseerd met de volgende bevindingen:
- Wegenareaal
- Weglengte
De weglengte in Nederland per wegcategorie kan onder andere geschat worden met gebruik van het Nationaal Wegenbestand (NWB) en de wegkenmerkendatabase (WKD). Het aantal kilometer weglengte is nog niet heel nauwkeurig in beeld te brengen, voor een belangrijk deel vanwege wegen met twee of meer rijbanen. - Kruispunten
Het aantal kruispunten in Nederland van verschillende typen en verschillende snelheidslimieten is op dit moment nog maar heel grof geschat. Deze schattingen zijn hoogstwaarschijnlijk niet nauwkeurig genoeg om kruispunttypen met elkaar te kunnen vergelijken. Wel wordt gewerkt aan een toevoeging van kruispunten aan het NWB, waardoor dit wellicht in de toekomst beter te doen wordt.
- Weglengte
- Verkeersintensiteitsgegevens
- Mogelijke bronnen van intensiteitsgegevens zijn 1) intensiteitstellingen op specifieke meetlocaties, 2) output van verkeersmodellen en 3) floating car data (FCD). De output van verkeersmodellen en FCD lijkt onvoldoende betrouwbaar om een goede inschatting te maken van met name intensiteiten op erftoegangswegen.
- Het Nationaal Dataportaal Wegverkeer (NDW) verzamelt gegevens over het verkeer op vooral het hoofdwegennet (HWN) en in mindere mate het onderliggend wegennet (OWN). Het telnetwerk voor het HWN is vrij dicht en de tellingen zijn via de website te downloaden. Daarnaast worden ook incidentele tellingen uitgevoerd door verkeersonderzoeksbureaus. Deze data worden niet altijd centraal opgeslagen en kunnen, in sommige gevallen, worden opgevraagd bij de bureaus of ingekocht. De dekkingsgraad (aantal telpunten/wegvak) is niet bekend maar verkeersbureaus beschikken over data van meer dan 7.000 telpunten op OWN. Dit zijn meestal tijdelijke tellingen uitgevoerd over een periode van één tot twee weken.
- Ongevallengegevens
- De enige geschikte bron om aantallen ongevallen te kunnen koppelen aan specifieke locaties en/of wegcategorieën, is het Bestand geRegistreerde Ongevallen Nederland (BRON). Dit bestand bevat alle meldingen van ongevallen bij de politie en deze ongevallen worden gekoppeld aan het digitale wegennet. Niet alle ongevallen zijn geregistreerd in BRON, vooral voor lagere ernsten en ongevallen zonder betrokkenheid van een motorvoertuig is de registratiegraad laag.
Methode
De primaire bron van verkeersdata voor dit onderzoek zijn verkeerstellingen van de onderzoeksbureaus Meetel en Dufec. In totaal zijn ongeveer 560 telbestanden – verspreid over heel Nederland en verdeeld over de vier snelheidsregimes – geleverd aan SWOV, waarvan na alle controles 452 bruikbaar bleken.
Meetel en Dufec tellen veel minder vaak op 60- en 80km/uur-wegen, waardoor de steekproef op deze wegen aanzienlijk kleiner was dan op 30- en 50km/uur-wegen (zie Tabel 1). Om die reden zijn aanvullende meetpunten toegevoegd uit bestanden van de provincies Zuid-Holland en Utrecht.
Tabel 1. Aantal tellingen per snelheidslimiet en per bron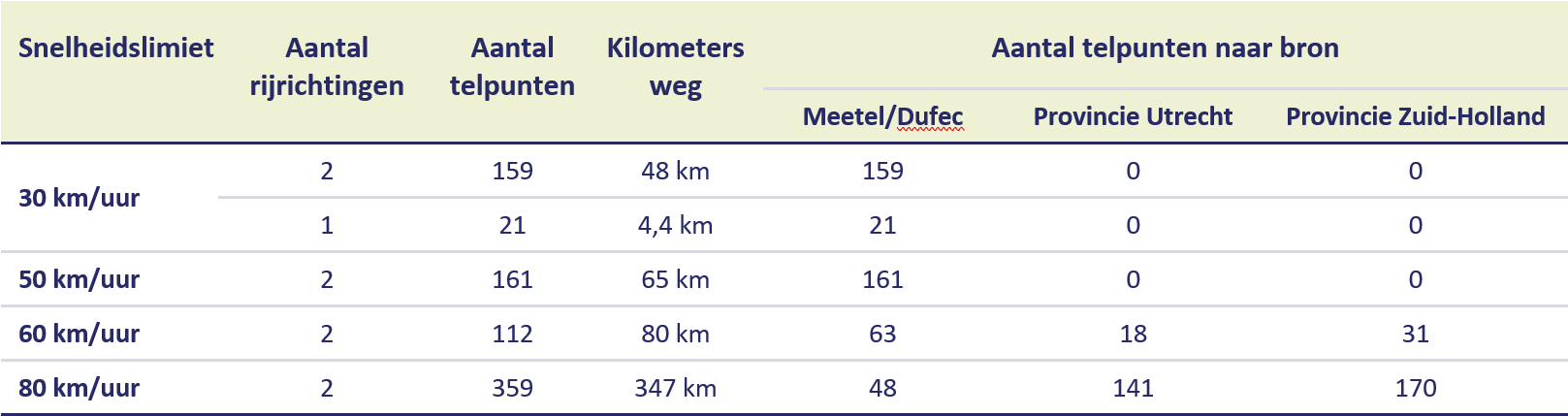
Er zijn twee verschillende benaderingen toegepast. In de eerste benadering worden risicocijfers berekend voor de steekproef van wegen waarvoor intensiteitsgegevens beschikbaar zijn. In dit geval worden alleen de weglengtes en ongevallen meegenomen die bij de steekproef van wegen horen waarvoor een verkeersintensiteit is bepaald. Deze methode levert een goede schatting van het risico op de wegvakken in de steekproef, maar het is de vraag in hoeverre de berekende risicocijfers representatief zijn voor de rest van Nederland, vanwege de betrekkelijk kleine aantallen ongevallen en lage ongevallendichtheden.
In de tweede benadering worden risicocijfers berekend op basis van landelijke gegevens over weglengte en het aantal ongevallen per wegcategorie (dus het totaal aantal ongevallen en weglengte van een categorie, bijvoorbeeld ETW30). In dat geval worden de verkeersintensiteiten op de steekproef van wegen als representatief beschouwd voor de betreffende wegcategorie in heel Nederland.
Omdat niet bekend is hoe representatief de verkeersintensiteiten zijn voor heel Nederland, worden risicocijfers in dit onderzoek op beide manieren berekend. Op beide manieren worden daarnaast ook ongevallendichtheden bepaald. Deze kunnen gebruikt worden om na te gaan of de wegvakken in de steekproef qua verkeersveiligheidsniveau representatief zijn voor de verschillende wegtypen/snelheidslimieten. Wanneer ze representatief zijn, is de ongevallendichtheid voor de steekproef vergelijkbaar met de ongevallendichtheid van de gehele populatie.
Resultaten
Verkeersintensiteiten
Binnen elke wegcategorie is een relatief grote spreiding aan gemiddelde etmaalintensiteiten te zien. De standaardafwijking is in alle gevallen relatief groot (bij 30km/uur- en 60km/uur-wegen zelfs meer dan 100% van het gemiddelde). In alle gevallen is sprake van een rechts-scheve (positief-scheve) verdeling en geen normale verdeling. Ondanks de grote spreiding lijkt te verdeling consistent te blijven, ook binnen subpopulaties van de steekproef; bij random ingedeelde subpopulaties van de verkeerstellingen worden in bijna alle gevallen geen significante verschillen gevonden.
Ongevallendichtheid en risicocijfers
De berekende ongevallendichtheden en risicocijfers zijn weergegeven in Tabel 2. Hier valt op dat de ongevallendichtheden op alle categorieën wegen, met uitzondering van de 50km/uur-wegen, aanzienlijk hoger liggen in de steekproefwegen dan op landelijk niveau. Waar dit verschil precies in ligt is niet direct te verklaren, anders dan dat de wegvakken in de SWOV-selectie relatief kort zijn en het bovendien een vrij kleine selectie betreft. Ook zou het kunnen liggen aan een oververtegenwoordiging van drukkere en/of gevaarlijkere wegen binnen de steekproefwegen met verkeerstellingen.
Kijkend naar de risicocijfers, zien wij voor de steekproefwegen en de landelijke schatting weer verschillende beelden. Voor de steekproefwegen hebben de 30km/uur-locaties een hoger risico op letselongevallen dan wegvakken met hogere limieten. Voor de landelijke schatting zien wij dat het risico op een dodelijk ongeval het laagst is op erftoegangswegen (30 km/uur en 60 km/uur) en het hoogst op gebiedsontsluitingswegen (50 km/uur en 80 km/uur). Kijkt men naar het risico op alle letselongevallen, dan ligt dit het hoogst op wegvakken binnen de bebouwde kom: 50- en 30km/uur-wegen.
Tabel 2. Samenvatting resultaten ongevallendichtheid en risicocijfers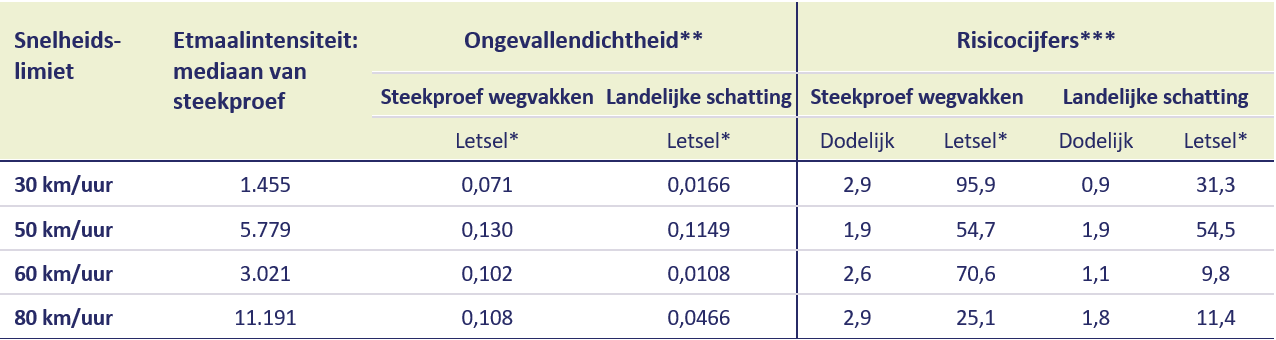
* Ongevallen met afloop: dodelijk, naar ziekenhuis en lichtgewond samen
** Gemiddeld aantal wegvakongevallen per jaar tussen 2011 t/m 2020 per wegkilometer
*** Aantal wegvakongevallen per jaar/miljard voertuigkilometers per jaar
Discussie
Tijdens het verzamelen en verwerken van de data zijn een aantal aandachtspunten naar voren gekomen:
- De incidentele verkeerstellingen bleken veel minder goed te gebruiken voor ons doeleinde dan aanvankelijk gedacht. Hierdoor moesten uiteindelijk alle locaties handmatig worden gecontroleerd, om zeker te zijn dat SWOV de correcte teldata en de daarbij behorende wegen had. Dit bleek een behoorlijk tijdsintensieve exercitie te zijn en zorgt voor grenzen aan de grootte van de steekproef.
- Voor de ongevallencijfers zijn wij beperkt tot BRON. De registratiegraad van vooral minder ernstige ongevallen en ongevallen zonder betrokkenheid van een motorvoertuig is laag in BRON. Ook is niet bekend in hoeverre de onderregistratie van het aantal ongevallen varieert over de verschillende wegcategorieën (een lagere registratiegraad op één wegcategorie ten opzichte van een ander zou kunnen zorgen voor een onterecht lager risicocijfer).
- De weglengte per snelheidslimiet is in 2022 geschat op basis van NWB en WKD. Omdat er aparte wegvakken zijn bij twee of meer rijbanen, en bij bijvoorbeeld op- en afritten, is de lengte aan wegvakken niet gelijk aan de weglengte.
Een andere belangrijke kwestie bij dit onderzoek was de representativiteit van de steekproef van wegvakken waarvoor intensiteitsgegevens beschikbaar zijn. Wanneer de eerste benadering gevolgd wordt, is het belangrijk dat het verkeersveiligheidsniveau van de wegvakken in de steekproef representatief is voor Nederland als geheel. Als dat niet het geval is, geven de risicocijfers wel een beeld van het risico op de wegvakken in de steekproef, maar niet voor de verschillende wegcategorieën in Nederland. Omdat de uiteindelijke ongevallendichtheden op de steekproefwegen in de meeste gevallen sterk afwijken van het nationale gemiddelde (zie Tabel 2), lijken de wegvakken op dit punt niet representatief te zijn. Om die reden levert de tweede benadering – bij gebrek aan een grotere steekproef – vermoedelijk een betere schatting. Bij deze tweede benadering is wel een belangrijke aanname dat de verkeersintensiteiten van de wegvakken in de steekproef representatief zijn voor dat wegtype op landelijk niveau. Ondanks de grote spreidingen per wegcategorie, leken de steekproeven volgens zogeheten t-toetsen groot genoeg om interne consequentie te tonen. De steekproeven uit verschillende bronnen (en verschillende regio’s) lieten bij 60- en 80km/uur-wegen echter wel significante verschillen zien, wat suggereert dat een nog grotere steekproef wenselijk zou zijn.[2]
Een andere belangrijke beperking van het onderzoek is de identificatie van de verschillende wegtypen. Op dit moment is alleen een onderscheid naar snelheidslimiet mogelijk, terwijl eigenlijk (ook) een onderscheid naar erftoegangswegen en gebiedsontsluitingswegen wenselijk is. Er zijn ook gebiedsontsluitingswegen met snelheidslimieten van 30 km/uur (GOW30), 60 km/uur (GOW60) en 70 km/uur en de verwachting is dat de weglengte van GOW30 en GOW60 de komende jaren toeneemt. Dit compliceert de actualisatie van risicocijfers.
Gegeven de hierboven besproken beperkingen van het onderzoek, moeten de gepresenteerde risicocijfers als indicatief beschouwd worden.
Aanbevelingen
Op basis van dit onderzoek worden een aantal aanbevelingen gemaakt voor de doorontwikkeling van risicocijferschattingen:
- Centraal databestand opbouwen met incidentele verkeerstellingen, ook op lagere-ordewegen
Met daarin de telgegevens en de gps-coördinaten van de telling en kenmerken van de telling. Op dit moment zijn de gps-coördinaten niet goed gekoppeld aan de data, waardoor het moeilijk is om een grootschalige set aan tellingen op te bouwen. - Aandacht voor de representativiteit van de steekproef
De gebruikte steekproef in deze studie bleek te klein voor de eerste benadering. Of de steekproef representatief is voor verkeersintensiteiten op deze wegcategorie in heel Nederland, dient opnieuw te worden uitgezocht. - Risicocijfers op landelijk niveau haalbaar
Met meer zekerheid over de representativiteit van de steekproef verkeerstellingen (punt 2) en een verbeterde datakwaliteit (punt 1) zou het berekenen van meer betrouwbare risicocijfers op landelijk niveau (landelijk aantal ongevallen en weglengte) haalbaar zijn. - Verdere onderverdeling in wegtypen
De grote spreiding in verkeersintensiteiten binnen één snelheidslimiet impliceert dat er mogelijk meerdere subcategorieën binnen de beschouwde categorieën te herkennen zijn waarvoor risicocijfers berekend kunnen worden. Er zouden verschillende intensiteitsklassen onderscheiden kunnen worden. Ook zou gekeken kunnen worden naar verschillende ontwerpvarianten binnen één snelheidslimiet en verschillende snelheidslimieten binnen één wegcategorie. Hiermee kan het risicocijfer verder worden verfijnd en zou het gebruikt kunnen worden om ontwerpvarianten met elkaar te vergelijken (en maatregelen te motiveren). Bij meer wegcategorieën is wel een grotere steekproef nodig en bovendien is het onderscheiden van verschillende ontwerpvarianten en verschillende typen wegen bij een gegeven snelheidslimiet niet goed mogelijk op basis van de beschikbare data.
[1]. Rijkswegen laten we hier buiten beschouwing, omdat risicocijfers voor rijkswegen worden besproken in de jaarlijkse monitor Veilig over Rijkswegen (zie bijvoorbeeld Arcadis & Sweco (2022). Veilig over Rijkswegen 2020: monitoringsrapport verkeersveiligheid van rijkswegen, Deel A: Landelijk beeld. Rijkswaterstaat Water, Verkeer en Leefomgeving (RWS-WVL). Uitgevoerd door Arcadis & Sweco, Rijswijk.)
[2]. Volgens ouder onderzoek uit 1998 zouden minimaal 2.500 wegvaklocaties (en 1.500 kruispunten) nodig zijn voor een representatieve steekproef (Hummel, T. (1998). Haalbaarheid kencijfers voor lagere-orde-wegen en langzaam verkeer. Deel 1: een inventarisatie van kosten en baten. R-98-23 I. SWOV, Leidschendam).
Updating risk rates for the secondary road network
Risk rates - the number of crashes divided by the distance travelled - are used to compare the safety level of different categories, such as different modes of transport or different road types. Risk rates are important when calculating road safety effects during the planning phase of infrastructure projects, when monitoring road safety developments, and when prioritizing certain roads/road types for implementing measures that need to be taken.
In 1985-2007, SWOV determined risk rates for the various road types in the Netherlands. Due to a lack of sufficiently reliable traffic volume data, particularly for distributor roads and access roads, these risk rates have not been updated since 2007. This sometimes makes it difficult for road authorities to provide insight into the road safety effects of large infrastructural interventions on the secondary road network, particularly at the level of road type/speed limit.
More traffic data are now available to estimate risk rates and crash densities (the number of crashes per kilometre of road length). Therefore, using available data sources, SWOV attempted to update the risk rates and crash densities - together referred to as 'key crash rates' - for various road types on the secondary road network.[1]
The study
First, it was determined which useful data sources are currently available. Second, a method was developed to estimate crash densities and risk rates using the available data. This method was then applied to arrive at updated crash densities and risk rates per road type. Application of the method also provides insight into the reliability of risk rates and the feasibility of a more structural updating of risk rates.
Data sources available
In order to estimate risk rates, information about roads, traffic volumes and the number of crashes on these roads is needed. This study inventoried possible sources with the following findings:
- Roads
- Road length
In the Netherlands, road length per road category can be estimated using the National Road Database (Nationaal Wegenbestand) and the Road Features Database (wegkenmerkendatabase). An accurate picture of the number of kilometres of road length cannot be given yet, largely because of roads with two or more carriageways. - Intersections
In the Netherlands, the number of different intersections types and disaggregated by speed limit has only roughly been estimated. These estimates are most likely not sufficiently accurate to compare intersection types. However, work is in progress to add intersections to the National Road Database, which may make this more feasible in the future.
- Road length
- Traffic volume data
- Possible sources of data on traffic volume are 1) volume counts at specific locations, 2) traffic model output, and 3) floating car data (FCD). For access roads in particular, the output of traffic models and FCD seem insufficiently reliable to estimate traffic volumes.
- The National Road Traffic Data Portal (Nationaal Dataportaal Wegverkeer) mainly collects data on traffic on the main road network and to a lesser extent on the secondary road network. The traffic count network for the national road network is quite dense and the counts can be downloaded via the website. These are generally based on permanent counting stations. Secondary counts are also conducted by traffic counting agencies. These data are not always stored centrally and, in some cases, can be requested or purchased from the agencies. The degree of coverage (number of counting stations/road segment) is not known but traffic agencies have data from more than 7,000 counting stations on the secondary road network. These usually concern temporary counts conducted over a period of one to two weeks.
- Crash data
- The only suitable source for linking crash numbers to specific locations and/or road categories is the database of registered road crashes in the Netherlands (BRON). This database contains all police registered crashes and these are linked to the digital road network. Not all crashes are registered in BRON; especially for lower severities and crashes without motor vehicle involvement.
Method
The primary source of traffic data for this study are traffic counts by the traffic counting firms Meetel and Dufec. A total of about 560 traffic count files - spread throughout the Netherlands and divided among the four speed regimes - were delivered to SWOV. Of these, 452 turned out to be usable after conducting the necessary checks.
Meetel and Dufec count much less frequently on 60- and 80km/h roads, so the sample on these roads was significantly smaller than on 30- and 50km/h roads (see Table 1). For this reason, additional counts were added from databases of the provinces of South Holland and Utrecht.
Table 1. Number of counts by speed limit and source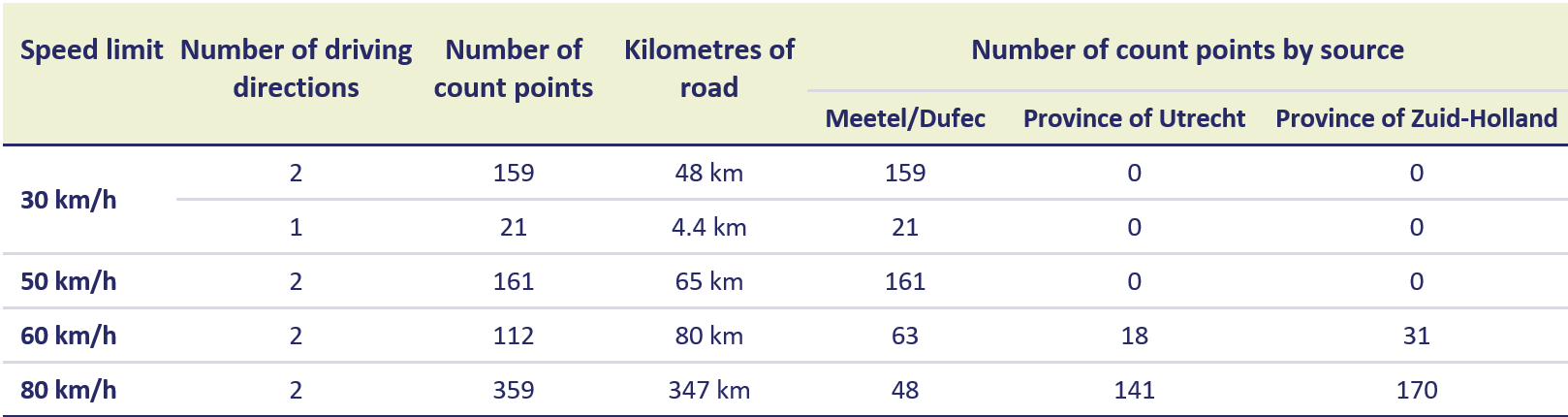
Two different approaches were used. Using the first approach, risk rates were calculated for the sample of roads for which traffic volume data were available. In this case, only those road lengths and crashes were included that belonged to the sample of roads for which the traffic volume had been determined. This method provides a good estimate of the risk on the road sections in the sample, but it is questionable to what extent the calculated risk rates are representative for the rest of the Netherlands due to the relatively small numbers of crashes and low crash densities.
Using the second approach, risk rates were calculated from national data on road length and the number of crashes per road category (i.e., the total number of crashes and road length of a category, e.g., ETW30 (Access Road 30)). In this case, traffic volumes on the sample of roads are considered representative of the relevant road category throughout the Netherlands.
As it is unknown how representative the traffic volumes are for all of the Netherlands, in this study risk rates were calculated in both ways. Crash densities were also determined in both ways. These could be used to check whether, in terms of the road safety level, the road sections in the sample are representative for the various road types/speed limits. If they are representative, the crash density for the sample is comparable to the crash density of the entire population.
Results
Traffic volumes
Within each road category, a relatively large spread of average daily traffic volumes can be seen. In all cases, the standard deviation is relatively large (for 30km/h and 60km/h roads even more than 100% of the mean). In all cases there is a right-skewed (positively skewed) distribution and no normal distribution. Despite the large spread, the distribution seems to remain consistent even within subpopulations of the sample; in randomly assigned subpopulations of the traffic counts, hardly any of the cases show significant differences.
Crash density and risk rates
The calculated crash densities and risk rates are shown in Table 2. Strikingly, the crash densities on all road categories, with the exception of the 50km/h roads, are significantly higher on the sample roads than at the national level. What causes this difference is not immediately apparent, other than the road sections in the SWOV selection being relatively short and the selection being rather small. The difference could also be due to an overrepresentation of busier and/or more dangerous roads within the sample of roads with traffic counts.
Looking at the risk rates, we again see different pictures for the sample roads and the national estimate. For the sample roads, the risk of injury crashes is higher on the 30km/h locations than on road sections with higher speed limits. For the national estimate, the risk of a fatal crash is lowest on access roads (30km/h and 60km/h) and highest on distributor roads (50km/h and 80km/h). For all injury crashes, risk is highest on urban road sections: 50- and 30km/h roads.
Table 2. Summary of results crash density and risk rates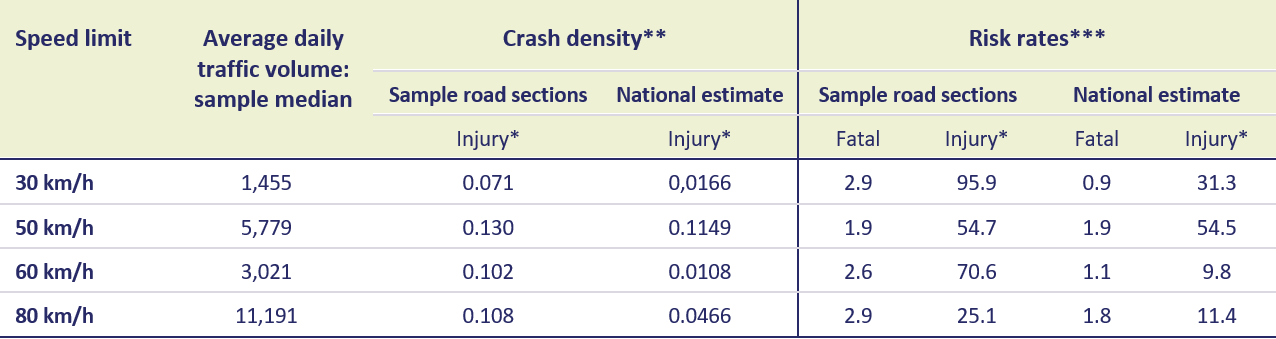
* Crashes with outcomes: fatal, to hospital, and minor injury combined
** Average annual number of road section crashes from 2011 to 2020 per road kilometre
*** Number of road section crashes per year/billion vehicle kilometres per year
Discussion
While collecting and processing the data, a number of concerns emerged:
- The incidental traffic counts turned out to be much less useful for our purpose than initially thought. Eventually, all locations had to be checked manually to make sure that SWOV had the correct count data for the roads referred to and selected in the sample. This proved to be quite a time-consuming exercise, which sets limits to the sample size.
- For crash rates, we are limited to BRON. In BRON, the registration rate of particularly minor crashes and crashes not involving motor vehicles is low. Also it is not known to what extent under-registration of the number of crashes varies across road categories (a lower registration rate on one road category compared to another could result in an potential incorrect lower risk rate).
- In 2022, road length by speed limit was estimated based on the National Road Database and the Road Features Database. Because there are separate road sections where there are two or more carriageways, and at entry ramps and exits for example, the length of road sections does not equal the road length.
Another important issue in this study was the representativeness of the sample of road sections for which volume data are available. If the first approach is followed, it is important that the road safety level of the road sections in the sample is representative of all of the Netherlands. If this is not the case, the risk rates give a picture of the risk on the road sections in the sample, but not necessarily for the different road categories in the Netherlands. In most cases, the final crash densities on the sample roads are very different from the national average (see Table 2), so the sample road sections do not seem to be representative in this respect. For this reason, the second approach – in the absence of a larger sample – presumably provides a better estimate. This second approach does make the important assumption that the traffic volumes of the road sections in the sample are representative of that road type at the national level. Despite the large spread in count data by road category, and according to Students-t-tests, the samples seemed large enough to show internal consistency. However, the samples from different sources (and different regions) did show significant differences on 60- and 80km/h roads, suggesting that a larger sample would be desirable.[2]
Another important limitation of the study is the identification of the different road types. Currently, only a distinction by speed limit is possible, while a distinction between access roads and distributor roads based on actual layout would (also) be desirable. There are also distributor roads with speed limits of 30 km/h (GOW30), 60 km/h (GOW60) and 70 km/h (GOW70), and the road length of GOW30 and GOW60 is expected to increase in years to come. This complicates the updating of risk rates.
Given the limitations of the study discussed above, the risk rates presented should be considered indicative.
Recommendations
Based on this research, a number of recommendations are made for the further development of risk rate estimates:
- Build central database with occasional traffic counts, on lower-order roads as well
Containing the count data and GPS coordinates of the count and characteristics of the count. Currently, the GPS coordinates are not properly linked to the data, making it difficult to build a large-scale set of counts. - Pay attention to sample representativeness
The sample used in this study turned out to be too small to use the first approach. Whether the sample is representative of traffic volumes on this road category nationwide needs to be re-examined. - Country-level risk rates feasible
With more certainty about the representativeness of the sample traffic counts (item 2) and improved data quality (item 1), calculating more reliable risk rates at the national level (national number of crashes and road length) would be feasible. - Further subdivision into road types
The large spread in traffic volumes within one speed limit may allow for identification of several subcategories within the considered categories for which risk rates can be calculated. Different volume categories could be distinguished. Different design variants within one speed limit and different speed limits within one road category could also be considered. In this way, risk rates could be further refined and could be used to compare design variants (and motivate remedial measures). With more road categories, however, a larger sample size is needed and, moreover, the available data will make it difficult to distinguish different design variants and different road types at a given speed limit.
[1]. Risk rates for national roads are discussed in the annual monitor Veilig over Rijkswegen [Safe on National Roads]. We therefore leave national roads aside here.
[2]. According to older research dating from 1998, a minimum of 2,500 road section locations (and 1,500 intersections) would be needed for a representative sample (Hummel, T. (1998). Haalbaarheid kencijfers voor lagere-orde-wegen en langzaam verkeer [The feasibility of key risk indexes for lower-order roads and slow traffic; Part 1: An inventory of costs and benefits]. R-98-23 I. SWOV, Leidschendam [With a summary in English])